
谷歌TurboQuant突破,解锁AI效率与标准化新赛道
一、技术解读(通俗版)
随着AI大模型的能力越来越强,一个核心痛点日益突出——“内存不够用”。就像我们用手机存太多照片会卡顿一样,大模型在处理长对话、复杂任务时,需要缓存大量中间数据(行业内称为“KV Cache”),这些数据会占用巨大的内存空间,不仅导致AI运行卡顿、响应缓慢,还会大幅增加硬件成本,成为制约AI普及的“卡脖子”问题。
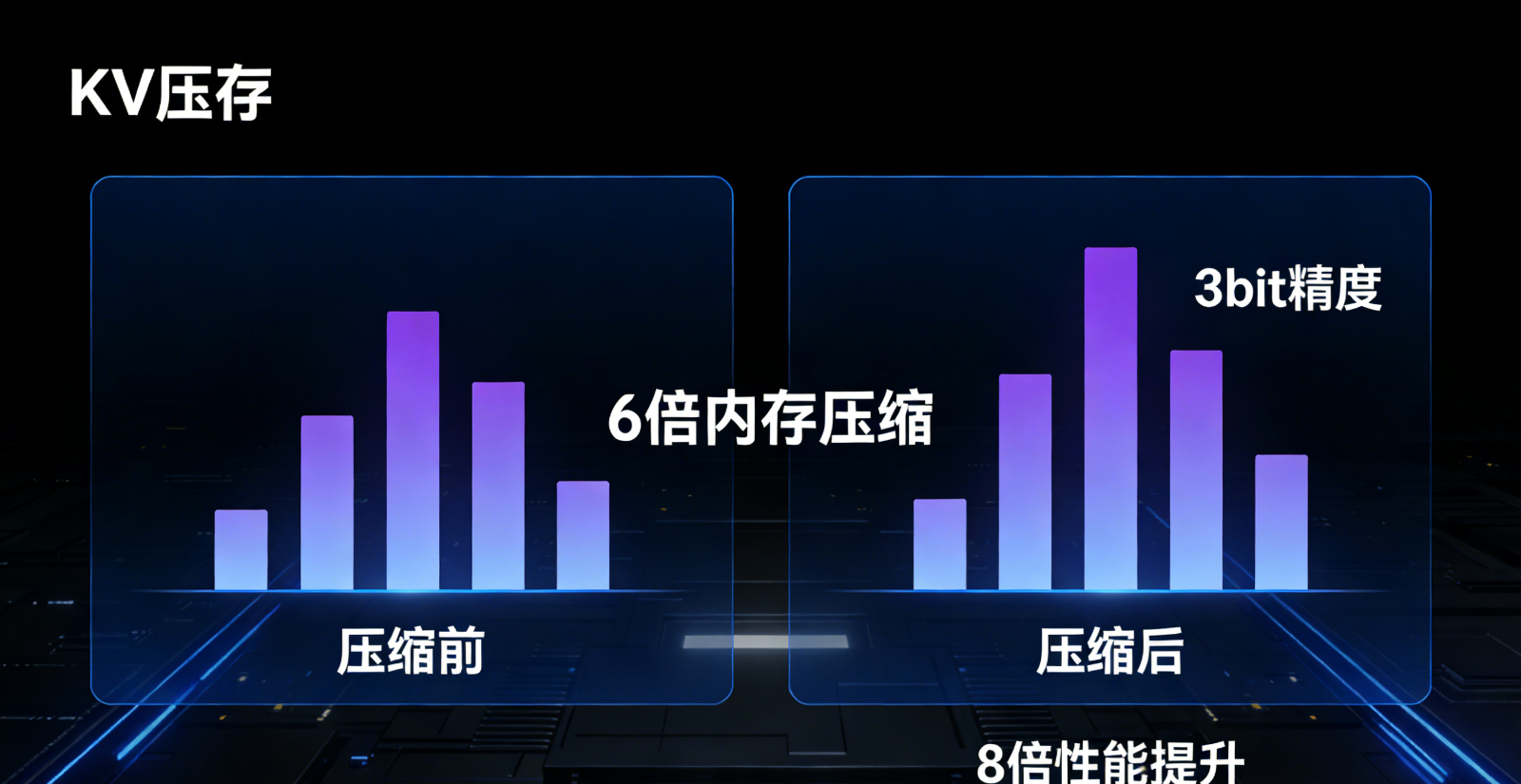
3月26日,谷歌研究院正式发布TurboQuant内存压缩算法,专门解决这一痛点。简单来说,这个算法就像一个“智能压缩工具”,无需重新训练或修改大模型,就能将KV Cache的内存占用压缩至原来的1/6(即6倍内存压缩效果),同时将AI的运算速度提升最高8倍,更关键的是,压缩后AI的准确率几乎没有损失,实现了“省内存、提速度、保精准”三者兼顾。
其核心技术突破在于打破了60年来的底层限制——通过“空间旋转”技术,将杂乱的高维数据转化为可预测的分布,再通过“1-bit纠错”机制,校准AI运算的核心指标,无需复杂的计算流程,就能实现极致压缩。更便捷的是,该算法无需提前“学习”数据特征,可实时处理AI运行中的动态数据,完美适配聊天机器人、智能搜索等实时交互场景。
二、应用场景分析
TurboQuant算法的落地,将让AI摆脱硬件限制,走进更多场景,尤其是对内存要求较高的领域:
1. 移动端AI场景:此前,复杂的大模型很难在手机、平板等移动端流畅运行,因为移动端内存有限。有了TurboQuant算法,手机端AI的内存占用将大幅降低,未来我们可以在手机上流畅使用大模型生成文案、编辑视频、进行专业数据分析,无需依赖电脑或云端,让AI更“便携”。有网友实测,将该算法应用于Qwen3.5模型后,内存占用缩小近5倍,移动端运行流畅度显著提升。
2. 企业级AI场景:对于需要处理大量数据的企业(如电商、金融、科研),AI模型的内存成本是一笔巨大开支。该算法可让企业在现有硬件设备上,运行更复杂的大模型,或同时处理更多用户的请求,比如电商平台的智能推荐AI,可同时响应百万级用户的请求,且不会出现卡顿,大幅提升运营效率、降低硬件投入成本。
3. 长文本处理场景:此前AI处理长文档(如百万字的法律文书、科研论文)时,容易出现“失忆”“卡顿”问题,TurboQuant算法可大幅扩展AI的上下文处理能力,让AI一次性处理相当于10部《红楼梦》的超长文本,为法律文档分析、科研论文综述、代码库全局理解等场景带来根本性变革。
三、行业影响展望
TurboQuant算法的发布,标志着AI行业的竞争重心从“比拼模型参数规模”转向“优化运行效率”,其对行业的影响将逐步显现:
第一,降低AI部署成本,推动AI普惠化。内存压缩技术的突破,让中小企业无需购买昂贵的高端硬件,就能部署高效的AI服务,打破“只有大企业才能用得起AI”的壁垒,激活长尾市场,让AI渗透到更多中小企业和细分领域,比如餐饮、零售等传统行业,可通过低成本AI实现智能记账、客户管理等功能。受此影响,美光、西部数据等存储巨头股价应声下跌,市场担忧AI内存需求前景生变。
第二,加速AI技术落地,催生新应用场景。随着内存瓶颈的破解,AI将在更多高要求场景实现突破,比如自动驾驶中的实时决策、医疗领域的精准诊断、工业领域的智能质检等,这些场景对AI的响应速度和内存容量要求极高,TurboQuant算法将为其提供核心技术支撑,推动AI从“实验室”走向“产业一线”。
第三,引发AI效率竞赛,推动技术迭代。谷歌的突破将倒逼其他AI厂商加快内存优化技术的研发,未来会有更多类似的压缩算法出现,形成“百花齐放”的竞争格局,最终受益的将是企业和用户——AI服务会越来越高效、越来越便宜,应用场景也会越来越丰富。业内人士认为,2026年后,AI竞赛的下半场将是效率竞赛,底层算法与工程优化将成为核心竞争力。
行业总结:AI进入“标准化+高效化”双轮驱动时代
未来,AI的发展将围绕“标准化”与“高效化”双轮驱动:一方面,词元将成为AI产业的“通用货币”,推动数据要素市场化、商业模式规范化;另一方面,内存压缩、算力优化等底层技术将持续突破,让AI更普惠、更高效。对于普通人而言,我们将迎来一个“AI无处不在”的时代——手机里的AI助理更智能,工作中的AI工具更高效,生活中的AI服务更便捷;对于企业而言,AI将不再是“奢侈品”,而是降本增效、提升竞争力的“必需品”。
立非 - Lifre ©️ 版权所有
